
Preface:
Compaction techniques combines multiple SSTables to a single SSTable to improve the performance of read operations by reducing disk I/O and to free space from deleted data.
In this article we will discuss about the size tiered compaction strategy.
Size Tiered Compaction Strategy:
Size tiered compaction strategy combine multiple SSTables which belong to a particular data size range.
This technique categories SSTables into different buckets and compaction process will run for each bucket indiviaully.
- Compaction is based on following properties:
- bucket_high (default 1.5)
SSTables added to a bucket if the SSTable size is less than 1.5 times average size of that bucket.
e.g. if SSTable size is 14MB and bucket avg. size is 10MB, then SSTable will be added that bucket and new avg. size will be computed the bucket. - bucket_low (default 0.5) SSTables added to a bucket if the SSTable size is greater than 0.5 times average size of that bucket.
e.g. if SSTable size is 7MB and bucket avg. size is 10MB, then SSTable will be added that bucket and new avg. size will be computed the bucket. - max_threshold (default 32) maximum number of SSTables to allow in a bucket for compaction.
- min_threshold (default 4) minimum number of SSTables in a bucket to start a compaction.
- min_sstable_size (default 50MB) The bucketing process groups SSTables that differ in size by greater/less than 50%. This results in a bucketing process that is too fine grained for small SSTables. All sstables are not matching ths criteria and having size less than min_sstable_size get into a single bucket whose avg. size is less than min_sstables_size.
- Sort SSTable according to size in descending order. After sorting above SStable we will have a list of sorted SSTables(in MB) as 100, 78, 60, 51, 34, 27, 19, 10, 7, 1.
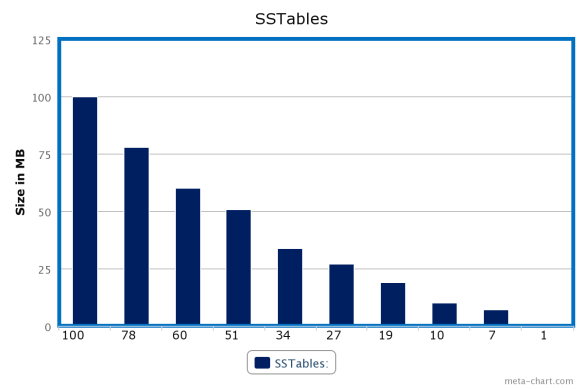
SSTable sorted before appearing for compaction
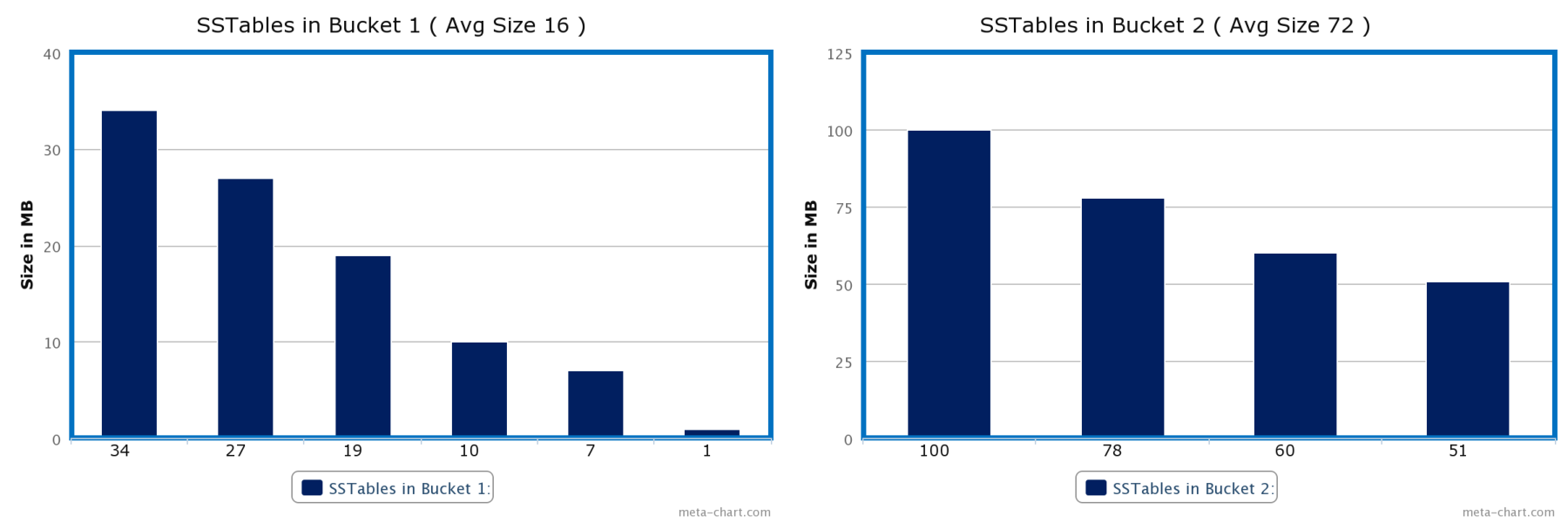
- Categories SSTables into a multiple buckets based on configuration and following condition :
IF ((bucket avg size * bucket_low < SStable’ size < bucket avg size * bucket_high) OR (SStable’ size < min_sstable_size AND bucket avg size < min_sstable_size))
then add the SSTable to the bucket and compute the new avg. size of the bucket.
ELSE create a new bucket with the SSTable.Following bucketing will happen with bucket_low as 0.5, bucket_high as 1.5, min_sstable_size as 32MB, min_threshold as 4 and max_threshold as 32.

Bucketing before compaction
- Buckets are sorted according to their hotness(CASSANDRA-5515) property. Hotness of bucket is sum of hotness of SSTables in bucket. Cold bucket will get the less priority than hot buckets for compaction.
- Those buckets do not meet the criteria of min_threshold will be discarded. Those buckets have SSTables more than max_threshold, will be trimmed to max_threshold and appear for the compaction. All SSTables in such bucket will be sorted according to hotness of SSTable and top (32/ max_threshold ) SStable will be considered.
- Size tiered compaction doesnt give any guarantee about column distribution of particular row. I may possible that columns of particular row-key belong to different SSTables. In such cases read performance will hit as read operation need to touch all SSTables where columns present.
- In worst case it might need exact amount of free space(100%) to combine SSTables.
Lets assume we have SSTables of sizes (in MB) as 78, 51, 100, 60, 19, 27, 34, 7, 1, 10.

SSTable before compaction starts
Let’s see how compaction algorithm works …
Algorithm:


Good article to provide an overview of the STCS, however it contains several grammatical errors which made the reading difficult at some points.